
Network traffic flows (flows) are useful for building a coarse-grained understanding of traffic on a computer network.
Following on from What is a Network Traffic Flow? and What is a Network Traffic Flow? (Part 2), this third post investigates flow metadata, how it adds value to flow analysis, and how to record and transport it. This is the good stuff, where flows become useful…

Figure 1 – What this blog post covers
(scroll up for top of post)
What is Flow Metadata?
Flow metadata describes characteristics of packets in a flow. This data about data (metadata) is coarser grained than individual packets, so takes up less space, is easier to analyse and scales better[1].
Uses for Flow Metadata
There are many uses for flow metadata, including:
- Security. Looking for changes in flow behaviour that may indicate a security incident. This could include detecting network intrusion, port scanning, denial of service attacks etc.
- Troubleshooting. Flow metadata can help retrospectively track down the cause of an incident by giving visibility of what happening on the network just prior to, and during an incident. Flow metadata can also provide indications of capacity issues through volume of data transferred, and can indicate the health of network protocols such as TCP.
- Billing. Flow metadata is often used for differential billing based on volume of traffic to/from specific locations.
Types of Flow Metadata
Flow metadata often includes aggregated counters, such as total data and packets, as well as environmental data such as times and interfaces. Types of flow metadata include:
- Flow Properties (aka ‘characteristic properties‘[2])
- Generally immutable (do not change) and include characteristics such as IP protocol and addresses and are often the same values used as flow keys[3].
- Treatment properties can include environmental features of the flow such as interfaces (ports),
- Flow Features (aka ‘measured properties‘).
- These are dynamic properties calculated across all packets i.e. average/maximum/minimum/sum/difference of metrics such as packets, packet size, start time, end time etc.
Flow Records
We need a way to store flow metadata, and we call this construct a flow record.
A flow record stores flow properties and flow features for a specific time period. In Figure 2 we see an example flow record for an SSH session, coloured to show the types of data.
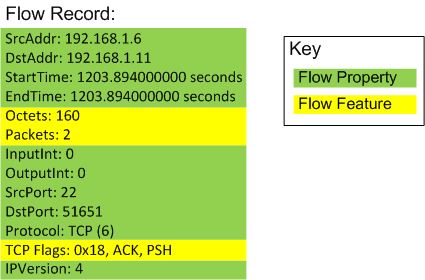
Figure 2 – Example Flow Record
This example flow record contains metadata about multiple packets in an SSH session (note: is unidirectional, i.e. one-way). As the added colouring shows, most of the entries in this flow record are for flow properties, and there are only 3 flow features: Octets (Bytes), Packets and TCP Flags. That’s a lot of invariant property information for not a lot of feature info! It is however worth remembering that the flow property information is valuable too – it says that a flow occurred, and identifies the endpoints and protocol etc.
Note the TCP flags in Figure 2; they are accumulated over the two packets that were observed (the downside to this is you cannot tell which packets had which combination of the indicated flags). The lack of a SYN flag tells us that this flow record didn’t cover the initial TCP 3-way handshake.
Methods to Capture and Transport Flow Metadata
Now that we’ve learnt about flow records, we need a way to transport them for off-box analysis, as where flow metadata is observed may not be where you want to analyse it. Additionally, there can be benefit from analysing flow records aggregated from multiple locations.
A short bit of history
There are various standards for recording and transporting flow records. Common standards include:
- NetFlow v5 (Cisco proprietary)
- NetFlow v9 (Cisco proprietary, added extensible templating and IPv6 support)
- IPFIX (IETF Standard), broadly based on NetFlow v9
NetFlow came about as a by-product of Cisco’s flow-based switching development, which needed to maintain a flow cache of flow records, and they patented the technology in 1996[4]. It started to see deployment in Cisco routers from the early 2000s.
The Internet Engineering Task Force (IETF) created an open standard for flow record export called IPFIX (IP Flow Information Export) from 2004, based on NetFlow version 9, which has since become the main non-proprietary standard flow records[5].
IPFIX adds functionality above that available in NetFlow, including support for vendor-specific fields and bidirectional flow records. I’m a fan of open standards so we restrict ourselves to IPFIX for the rest of the post; however the same principles generally apply to NetFlow (think of IPFIX as NetFlow v10).
IPFIX Architecture
In the terminology of IPFIX, flow records are exported and collected, as per Figure 3.
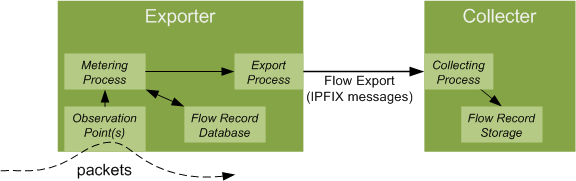
Figure 3 – IPFIX Architecture (high level)
- The Exporter observes packets (note: can filter/sample/aggregate them), turns packets into flow records and sends them to the Collector as IPFIX messages.
- The Collector receives the IPFIX messages, identifies and decodes them, and stores them for analysis.
The architecture is many-to-many, thus an exporter can send to multiple collectors and a collector can receive messages from multiple exporters.
Partial flow records
A potential problem with measuring flows is they may be long lived (I have seen a few flows last more than a month in a real network), and thus you may not find out about them till long after they started. This is a problem for applications that need timely data to take actions, such as security use cases.
The solution is to chop up longer-lived flows into multiple flow records via a mechanism called flow expiration, based on configurable rules to expire the flow based on some combination of:
- Time since last packet seen (i.e. has the flow become stale?)
- Time since last export (i.e. have we reported on the flow recently?)
- Indication that the flow has finished, such as FIN/RST flags on TCP flows
Flows can also be expired if the exporter runs out of resources (i.e. memory exhaustion). Expired flows are exported to the collector(s), and any subsequent packets in the same flow start a new flow record.
Exporters will often implement a cache to hold flow records, and there is optimisation applied to the process that receives packets and searches to see if they belong to an existing flow.
IPFIX the Protocol
The IPFIX protocol[6] transmits flow records and associated information, and is ‘fire and forget’, i.e. it is push-only and does not support responses back from the collector[7].
IPFIX sends data over the network in packets called IPFIX messages, as per Figure 4.

Figure 4 – IPFIX Message Structure
Transport Protocol
IPFIX is designed to be independent of the transport protocol; however the RFC mandates support for Stream Control Transmission Protocol (SCTP) with optional support for TCP and UDP[8].
Where reliability is required, SCTP (with partial reliability extension) is preferred over TCP as SCTP will try resending the missing IPFIX message only a set number of times and thus not cause blocking of other messages. SCTP however may be difficult to implement as it requires protocol support in both the exporter and the collector, and also in any intermediary firewalls. UDP can be used, but be careful as it does not implement congestion control, so could overload the network, and it does not implement any reliability mechanism so dropped messages will not be recovered[9].
In practice, I’ve never seen SCTP used, but UDP has worked fine in a data centre network and TCP once caused an exporter to have a very bad day (read that as an outage) due to resource exhaustion… YMMV.
Message Format
Each IPFIX message contains a message header and one or more sets, each of which can be one of three types:
- Template Set
- Options Template Set
- Data Set (contain flow records)
All sets have a header that contains a Set ID and Length, and contain one or more records.
The Set ID field identifies the type of set. Valid values are:
Template Set ID: 2 (reserved value)
Options Template Set ID: 3 (reserved value)
Data Set ID: > 255 (dynamic value)
Information Elements
Information Elements (IE) are standardised descriptions of types of information supported by IPFIX. Each IE contains a name, elementID, description, dataType and status, and the list of IEs is held by IANA[10]. Here is an example IE:
|
Key: |
Value |
|
ElementID: |
2 |
|
Name: |
PacketDeltaCount |
|
Abstract Data Type: |
unsigned64 |
|
Data Type Semantics: |
deltaCounter |
|
Status: |
current |
|
Description: |
The number of incoming packets since the previous report (if any) for this Flow at the Observation Point. |
|
Units: |
packets |
Templates
NetFlow version 9 introduced the concept of templates to make the information carried extensible and IPFIX continues this scheme. Templates are lists with entries that pair Information Elements and field lengths.
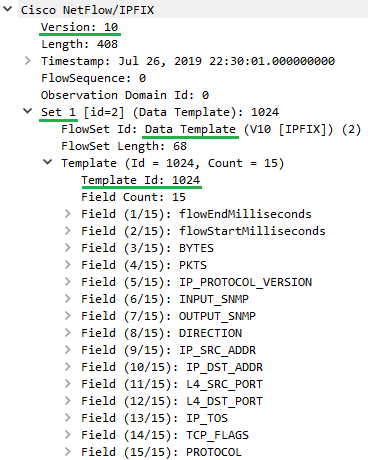
Figure 5 – IPFIX Template Example
In Figure 5 we see a Wireshark decode of an IPFIX message (note: IPFIX is version 10) that contains a number of sets. The first set is a template as indicated by FlowSet Id of 2 and has template id of 1024 and contains 15 fields.
More on template ids soon, but worth noting they can range from 256 to 65535 and template ids are different to flowset ids.
When we expand some of the template field specifiers (Figure 6) we see that they comprise of a code for their type (Information Element) and field length. Note that for enterprise-specific IEs there would be a third field called ‘Enterprise Number’ as well[11] (not shown here).
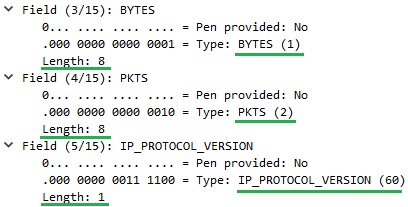
Figure 6 – IPFIX Template Example with Expanded Fields
Further downs the same IPFIX message (although it could have been in a subsequent one) we see Set 5 which contains 2 flow records, as per Figure 7.
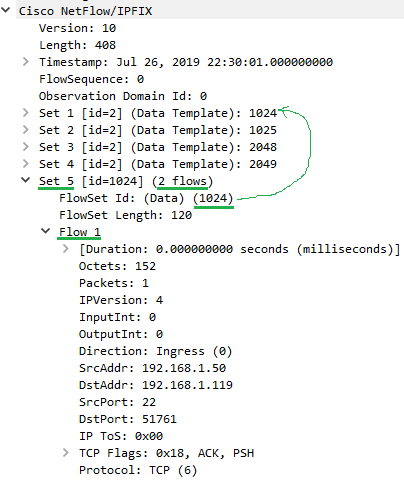
Figure 7 – IPFIX Flow Record Example
Note how the FlowSet ID matches a Template ID. This tells the Collector what template to use to unpack the flow records. Also note that the FlowSet ID could reference a template that was sent in a previous IPFIX message…
What IPFIX does with templates is to provide an extensible and efficient way to transport flow records – the information about fields/lengths is in the template and the flow records are efficiently encoded with just the field values in binary. The mapping of field names (IEs) back to how they should be interpreted is handled out-of-band via reference to the IANA registry as required.
Other Information
IPFIX can also export other information, including information about the exporter. See RFC 7011 for more information.
Extending IPFIX
IPFIX brings the opportunity to do more with flows.
Flow Features
Can we use IPFIX to get more flow features than just octets/packets etc.? Hell, yes! We have complete flexibility with the template model, so now it just comes down to the capabilities of the exporter.
IANA define almost 500 IEs that IPFIX can support, everything from minimumIpTotalLength (ElementID 25 – Length of the smallest packet observed for this Flow. The packet length includes the IP header(s) length and the IP payload length) to tcpWindowScale (ElementID 238 – The scale of the window field in the TCP header). It’s likely that anything you might want to measure about a flow is already specified in the IANA list.
If not, another list of potential flow features to measure can be found in the paper ‘Discriminators for use in flow-based classification‘[12] and these could be used in an enterprise-specific context (if you’re willing to do some coding…)
Reducing Duplication
You may have noticed a lot of repeated information across multiple flow records for the same flow. Back in Figure 2, most of the flow properties were invariant (example: source and destination IP addresses), so would be identical in the next flow record for the same flow. This seems like a bit of a waste of bandwidth and storage, so the good folk at IETF came up with a solution in the form of RFC 5473[13]
Bidirectional Flows
For bidirectional flows (i.e. TCP) it is useful to measure flow features across packets in both directions to get insights into response times, protocol errors and recoveries etc.
There’s an RFC for doing this with IPFIX – check out RFC 5103[14].
Wrapping it all up
In this post we delved into flow metadata, why it is useful, how it is recorded as flow records and how they can be transported. Hopefully this post has been of use to you.
[1] For more on benefits of flow metadata, see https://is.muni.cz/repo/1181098/flow-monitoring-explained-paper.pdf
[2] See: https://www.ietf.org/rfc/rfc5470.txt
[3] Flow keys are values used to identify the flow, see What is a Network Traffic Flow? post
[4] Cisco NetFlow patent: https://patents.google.com/patent/US6243667B1/en
[5] Excellent IETF slides on IPFIX history and architecture: https://www.ietf.org/slides/slides-edu-ipfix-00.pdf
[6] For IPFIX protocol see https://tools.ietf.org/html/rfc7011
[7] IPFIX does not support responses – see https://tools.ietf.org/html/rfc7013
[8] See section 10.1 of RFC 7011: https://tools.ietf.org/html/rfc7011
[9] See ‘Flow-based measurement: IPFIX development and deployment’ https://www.jstage.jst.go.jp/article/transcom/E94.B/8/E94.B_8_2190/_pdf
[10] For IANA list of Information Elements, see: https://www.iana.org/assignments/ipfix/ipfix.xhtml
[11] For more on template field specifiers, see RFC 7011 section 3.2 (https://tools.ietf.org/html/rfc7011)
[12] ‘Discriminators for use in flow-based classification‘ paper: https://qmro.qmul.ac.uk/xmlui/bitstream/handle/123456789/5050/RR-05-13.pdf?sequence=1
[13] RFC 5473 Reducing Redundancy – see: https://tools.ietf.org/html/rfc5473
[14] Bidirectional Flow Export, see: https://tools.ietf.org/html/rfc5103

One thought on “What is a Network Traffic Flow? (Part 3)”