
Apache NiFi facilitates the movement of data between systems. This free open-source software can ingest, manipulate and send/store data for batch and real-time use cases.
NiFi is kind of like an electricity grid, but for data. Where electrical grids connect many types of generation (solar, wind, hydro etc.), NiFi can ingest multiple types of data. And that data can be manipulated and controlled to go to many destinations. Here’s NiFi at a super-high level:
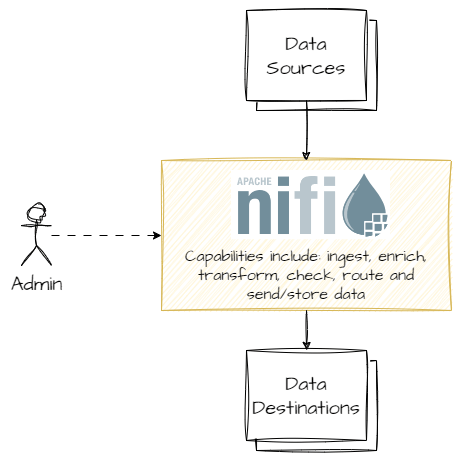
The name NiFi originates from the NSA[i], and is a portmanteau of “NiagraFiles”, the internal name for their system to manage the flow of intelligence information. The NSA used NiFi to “prioritize data flows more effectively and get rid of artificial delays in identifying and transmitting critical information”[ii], and open-sourced NiFi to the Apache Foundation in 2014, where there has been subsequent development by members of the open-source community[iii].
Usage of NiFi is becoming common in industry[iv], thanks to useful features such as:
- Comes with many pre-built modules (processors), reducing the need for custom coding.
- Easy-to-use drag-and-drop web interface for no-code / low-code development.
- Built-in data provenance, so you can inspect data to see where it came from and what was done to it.
- Extensible. Write your own processors, if needed.
- Guaranteed delivery (or at least capable of good error handling).
NiFi implements a type of Flow-Based Programming. To understand how NiFi works we need to cover a few definitions:
FlowFiles are units that carry data (content) and metadata (attributes):
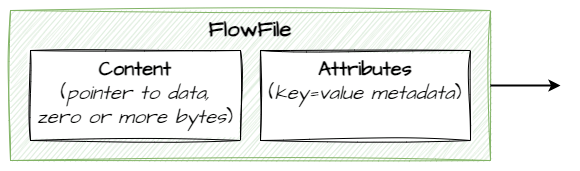
NiFi is data agnostic so the content of a FlowFile can pretty much be anything – unstructured data such as an image file, structured data such as a record, or even a database table with many records.
Attributes are key-value pairs and can be added/modified/referenced as the FlowFile passes through NiFi.
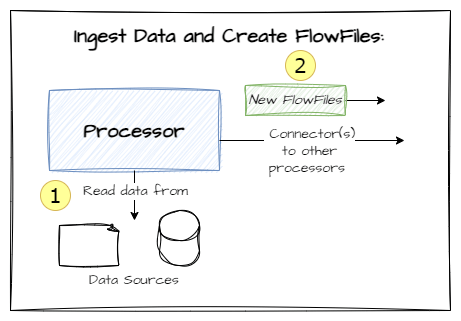
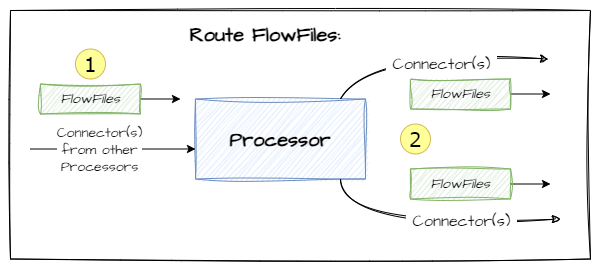
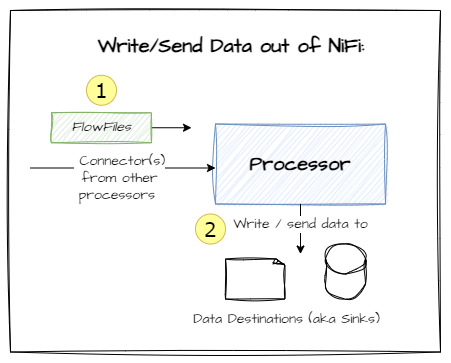
Next up, we have Processors. These are software modules that act on FlowFiles, with access to read/write their attributes and content.
Some processors have the capability to read in data from external sources (i.e., files, databases etc.) and using that data to create and send FlowFiles to other processors. Others have capabilities including updating FlowFiles, routing them and finally some specialise in sending data outside of NiFi using a variety of mediums and formats. Here are some common types of processor pattern:

NiFi comes with processors to read / write data from many sources including files, Kafka, SFTP, various cloud provider services, HTTP, MongoDB, Elasticsearch and many more. At the time of writing there are 349 built-in processors to choose from. Here is example of the Add Processor screen:

Processors are strung together using Connectors, which are single-direction links with a queue for temporary storage of FlowFiles. They have options for scheduling algorithms and even back-pressure to inform the upstream processor to slow down or halt transmission of FlowFiles.
A DataFlow is the name for a set of Processors, Connectors and other NiFi components, configured to meet a business need, and they are constructed on the web user interface backdrop called the canvas.
A Process Group is a drill-down grouping that holds a DataFlow (and optionally more levels of Process Groups), allowing separation of DataFlows to make comprehension easier and change less risky.
So, how does this all look in NiFi? Here is part of an example DataFlow, showing a Processor and a Connector:
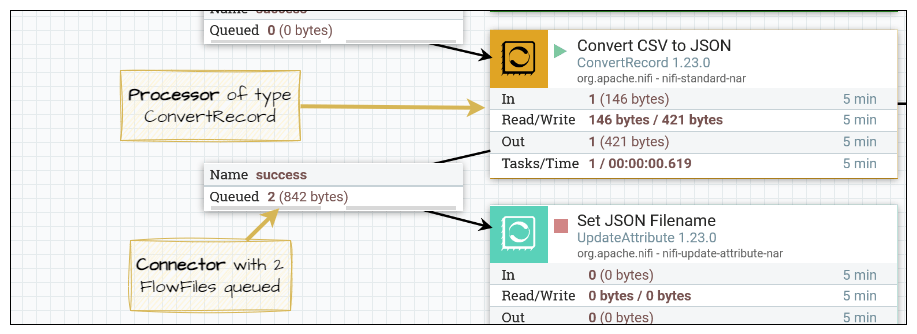
We can open the connector and see the queued FlowFiles:

Each FlowFile can be further inspected to see the data, attributes, and lineage.
When to Use NiFi
Consider using NiFi for moving data between systems, and possibly enrichment/transformation/routing along the way. Example data engineering use cases include Extract/Transform/Load (ETL) and Extract/Load/Transform (ELT) patterns. NiFi could for example extract data from sources such as databases, transform it by changing the format and load it into a destination data lake. Record-oriented processors can perform operations efficiently on an entire data set within FlowFiles without need to split into individual records.
Another use case is event-driven architecture. NiFi can receive events, normalise them and extract parameters to use to route the events to specific destinations.
When to not use NiFi?
NiFi may be less suited to use cases that require storing state and performing calculations across multiple items. If your use case goes beyond moving data and simple transformation then consider using NiFi in combination with other software (i.e., Apache Kafka, Airflow, Storm, various databases etc.) to carry out more advanced processing.
Wrapping it Up
This post covered just the basics of NiFi – what it is, types of use cases to use it for, and names of key components. There is much more to this powerful application, including clustering, design best practices etc. We have barely scratched the surface, but hopefully this has whetted your appetite to learn more about it.
For hands-on NiFi experience, check out my second blog post on NiFi which features a container-based demo.
More Information
Here are some NiFi video channels that I found useful:
- Steven Koon instructional NiFi videos on YouTube: https://www.youtube.com/watch?v=NC3IlbjrKeA
- Mark Payne, co-creator of NiFi: https://www.youtube.com/@nifinotes5127/videos
- NiFi Introduction by Stephane Maarek on YouTube: https://www.youtube.com/watch?v=-T9xuBMfI50
[i] NiFi came from NSA, see https://media.defense.gov/2021/Aug/11/2002828754/-1/-1/0/TTP-SUCCESS-NIFI.PDF
[ii] NiFi NSA use case, see https://www.nsa.gov/Press-Room/Press-Releases-Statements/Press-Release-View/Article/1649337/nsa-releases-first-in-series-of-software-products-to-open-source-community/
[iii] NiFi is under active development on GitHub: https://github.com/apache/nifi
[iv] Examples of companies using NiFi: https://nifi.apache.org/powered-by-nifi.html

For more NiFi information https://github.com/tspannhw/EverythingApacheNiFi
LikeLiked by 1 person