
In the world of IT architecture, coupling is a much talked about concept. But what is coupling, why is it important and what techniques/patterns can we use to optimise it?
That’s a lot to unpack, so let’s start with an example outside IT. Consider this trendy all-in-one desk lamp:

It looks lovely, but what happens if the bulb fails, or you want to change the light colour? It is tightly coupled because the bulb component cannot be replaced separately, so the whole lamp must be replaced in these circumstances.
Contrast it to this lamp:

Certainly not as stylish, but it has a separate bulb that can be replaced with any bulb of the correct standard[1]. The bulb doesn’t care what lamp it is in, and likewise the lamp doesn’t have an opinion on the bulb, as long as it is the right standard.
The bulb could be this: or even this:
or even this: 
In this example we say the lamp and bulb are loosely coupled, as they can be changed independently of one another (the principle of interchangeability).
So which lamp is better?
Coupling in IT
Back in IT, coupling is the measure of how much a change to one component affects other components in the system.
At one extreme, tight coupling is where change in one component significantly affects other components. Towards the other end of the spectrum, loose couple is where changes in one component have little to no effect on other components. Even further across on this spectrum we have decoupled, but more on that later.
Loose coupling is a useful property to have when we want to work on one part of a system or program without having to worry about impacts elsewhere (known or otherwise), and to minimise how much change is required (i.e. limit the scope of the change). Specifying types and locations of couplings is generally part of the IT architect role – ensuring key decisions that are hard to change later are properly considered[2]
Examples
In software, tight coupling could be a class that calls an internal function of another class:
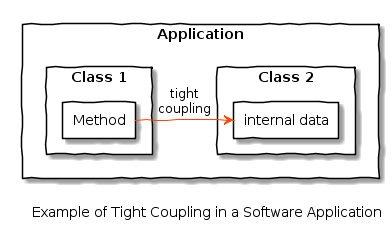
This is a strongly discouraged pattern, as a programmer altering Class 2 may not realise Class 1 is calling the internal data and inadvertently break things when updating the code.
Tight coupling software can also cause an application to become a monolith by breaking modularity, contributing to the app becoming a ‘big ball of mud‘ that is unpickable[3]. Modularity is important for testing too – tight coupling can lead to inability to construct effective unit tests.
Loose coupling, on the other hand, is where the coupling is independent of the internal details. In software it might look like this, where a class exposes a consistent public method that allows the internal details to be changed independently:
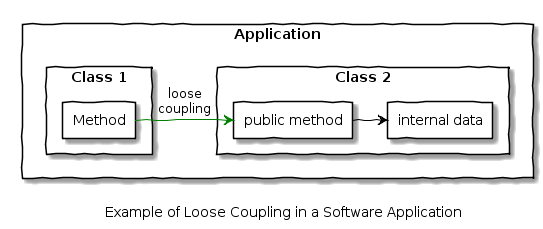
Now, let’s consider distributed systems (the main focus of this post) – these are systems of components linked by data networks. Tight coupling in this context could be an application that uses a database, where the database cannot be upgraded or swapped without updating the application code:
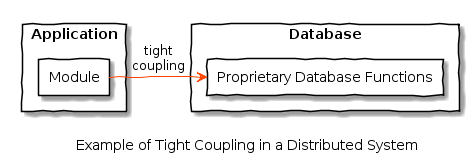
The application and database are thus lock-stepped – one cannot be changed without changing the other. Tight coupling often results in more difficult and expensive changes, affecting the maintainability of the system.
The coupling in this example could be loosened by addition of an Application Programming Interface (API) to abstract the internals of the database:
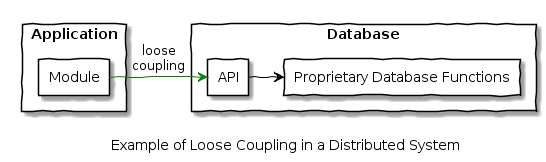
In both examples of loose coupling, a façade is used to abstract from internal details, reducing the level of coupling.

A Façade in Building Architecture hides internal changes within a consistent outer shell
Decoupling
We’ve covered loose and tight coupling, so what is decoupling?
Decoupling is where components are mediated – that is they don’t even know about each other, because they talk via an intermediary:
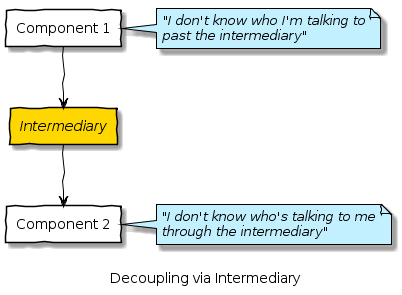
Decoupling has multiple benefits including ability to inspect data and ensure compliance, fan out to multiple destinations and even perform transformations on the data in the intermediary component.
Measuring Coupling
The degree of coupling (in a distributed system) can be measured by assessing technical characteristics in multiple dimensions[4], including:
Interface Openness. Can one component be changed out for another component that has same outer spec without impact elsewhere? A continuum of the platform dimension where we assess based on the interface model may look like:
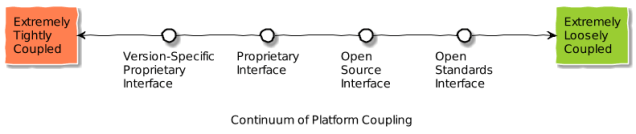
Be aware that even when an intermediary is used, coupling can still be tight if the format is restrictive (i.e. proprietary)
Interaction. An operation that must complete in another component before control is returned is called synchronous and is tightly coupled as changes in responsiveness of the second component will impact the first. Contrast this to a loose time coupling that is asynchronous – i.e. ‘fire and forget’ and ‘eventual consistency’. A continuum of the interaction dimension may look like:

State. The protocols for maintaining a shared state between components increase coupling; whereas passing state in messages avoids this:

Mediation. Assess how the coupling is mediated:

Versioning. How does the coupling deal with changes over time:

These are technical characteristics that provide some degree of objectivity to assessing couplings; however a complimentary approach could be to also (or instead) assess the outcome of the coupling in terms of fault tolerance, vendor fungibility, complexity, performance, cost etc.
Security is another consideration that hasn’t been covered. In some environments there will be requirements to authenticate/authorise couplings as well as protect data in transit and at rest. Security solutions to these requirements may impact the tightness of couplings.
Why choose Loose Coupling?
There are many reasons to architect loose coupling into a solution, including:
Maintainability
No solution is ever complete and finished. There will always be a need to iterate over time – whether it is bug fixes, feature enhancements or security patches. The business requirements of today will change over time, sometimes quickly. Loose coupling helps maintainability by making it easier to change only particular components or modules of the solution, without having a wider scope and impact.
Availability
The type of coupling not only has an impact on maintenance and changes to the system, but also to availability. Tight synchronous couplings can lead to cascading failures that worsen the impacts
For example, if a component relies on a second component to complete an operation before it can finish, then the first component is tightly coupled to the second. Consider this example in a working state:
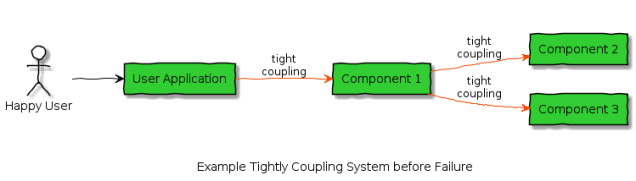
If Component 2 fails (or slows down) then Component 1 is also impacted due to the tight coupling:

A tightly coupled synchronous system is often only as strong as its weakest component. If this was a website with a widget not working, would you want the whole site down, or mostly working with just the widget displaying an error (or some nice message)?
Dev Team Considerations
Loose coupling / decoupling is also beneficial for scaling development teams – teams can independently code, test and release, at their own cadence, no longer blocked by waiting on other teams.
Vendor Fungibility
IT vendors love selling their products into businesses. If you’re the architect assessing vendor products then carefully consider coupling. Loose coupling helps to make vendors fungible (interchangeable), and this should be a key goal, as vendors can become complacent if their product is difficult to swap out. Vendors will of course offer you different perspectives on this…
When Tight Coupling may be a Good Idea?
The world is generally full of trade-offs, rather than perfect solutions, and couplings are no different. There are likely to be trade-offs from loose couplings which may include added complexity through more components and interfaces, and potentially lower efficiency. In some cases there may be little choice due to prior product selection (as in the all-in-one lamp analogy). Generally the benefits of loose coupling will win out where choice is available, but be aware of the risks of over-engineering and unnecessary complexity that loose coupling could introduce.
Useful Loose Coupling Patterns
There are various patterns/techniques to consider when architecting a system to loosen couplings; a small sample is included here:
Microservices
A popular architecture style for loose coupling in distributed systems is microservices, where well-defined interfaces enclose one or more components that implement a single business function in what is known as a bounded context[5].

Couplings to the microservice should be loose through a well-defined versioned interface.
API Gateways
An API gateway is generally a reverse proxy that sits in front of multiple microservices providing a single entry point for different types of consumers to call APIs. They can provide security and improve performance by reducing the number of round trips.

API Gateways loosen couplings by acting as an intermediary, and also hides the interface details of the back-end services, allowing these services to be changed independently of the client application.
Event-driven Architecture
A classic pattern for decoupling in systems architecture is the use of publish–subscribe (pub/sub) event messaging pattern, using a component such as Kafka for the intermediary event store. A high-level example is shown below:
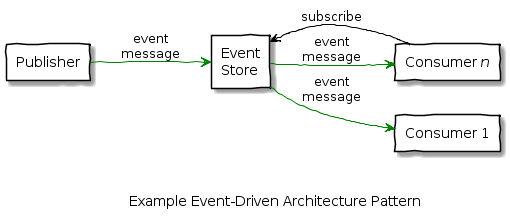
Publishers publish events as messages to an event store and consumers subscribe for types of event (topics) and these are pushed to them as they occur. Publishers have no knowledge of who the consumers are, and do not require any response from them, so this is an asynchronous pattern. Publishers do need to send their messages in an agreed standard format so consumers can reliably interpret them.
Bulkheads
Bulkheads in a nautical context are walls on a ship that stop a hole in the hull from sinking the ship by stopping the water from spreading to other sections. The IT context is isolating resources by service to stop capacity issues spreading and affecting other services (i.e. reducing contagion).
Circuit Breakers
A circuit breaker monitors the status of external synchronous calls – if they start timing out or otherwise failing it ‘trips’ and provides immediate error saving resources and time being tied up waiting for the call to fail[6]. They should regularly reset to be able to automatically re-establish service when the backend service becomes available again. Think of them as a pressure-release valve on tightly time-coupled connections that saves the whole system from blowing up.
Caching
Caching can be used in front of servers and databases to reduce load and improve fault tolerance.
Wrapping it up
Hopefully this post has been a useful introduction to coupling, both for software and distributed systems, why it is an important consideration, and has provided some ideas on techniques to loosen couplings.
Just as choosing to buy a lamp with changeable bulb gives you flexibility and serviceability; IT architecture decisions need to be made with a mind to the future, not just the needs of now. There are of course trade-offs and seldom any perfect answers. Architecting couplings needs to balance ideal state against potential increases in complexity and other trade-offs.
Further Reading
Loose Coupling and Architectural Implications presentation by Prof. Frank Leymann:
Cascading Failures:
https://medium.com/@adhorn/patterns-for-resilient-architecture-part-2-9b51a7e2f10f
References
[1] Assuming the bulb is not more than the maximum wattage the lamp supports, as this could be a fire risk
[2] See http://www.sergei2c.com/2020/01/agile-bridge-building.html
[3] See https://www.simplethread.com/why-do-we-keep-building-tightly-coupled-software/
[4] The dimensions shown are a rough and simplified subset of the facets described in “Why is the Web Loosely Coupled? A Multi-Faceted Metric for Service Design” by Cesare Pautasso and Erik Wilde (2009) https://design.inf.usi.ch/sites/default/files/biblio/restws-www2009.pdf
[5] Further reading on microservices: https://martinfowler.com/articles/microservices.html
[6] A good explanation of circuit breakers is at https://martinfowler.com/bliki/CircuitBreaker.html
