
Network traffic flows (flows) are useful for building a coarse-grained understanding of traffic on a computer network. Flows provide a convenient unit for the measurement and/or treatment of traffic.
Following on from What is a Network Traffic Flow?, this second post delves into Internet layer flow considerations. Previously, we found that the definition of a flow is mainly arbitrary, primarily driven by the capabilities of hardware/software, and the use cases. We now delve further into the considerations around specific features and behaviours of IP.
Figure 1 – Where this Blog Post fits in the Internet Protocol suite
IP Versions
Currently, there are two versions of Internet Protocol in use on the Internet; IPv4 and IPv6. Both work with the forward and reversed 5-tuple and 3-tuple flow keys from part 1, as per the IPv6 5-tuple example in Figure 2.
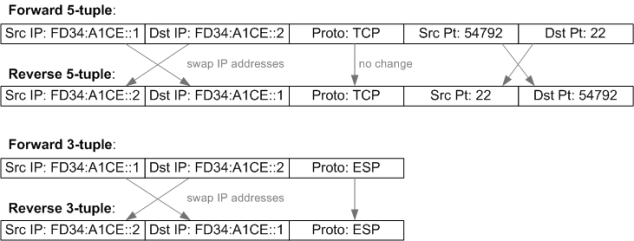
Figure 2 – IPv6 Flow 5-tuple and 3-tuple Examples
A key difference worth discussing is the IPv6 flow label, a field introduced in the IPv6 fixed header[1], as per Figure 3.

Figure 3 – Flow Label in IPv6 Packet Header
IPv6 flow labels are unidirectional, thus flow labels are different in each direction. Note that a flow label set to 0 indicates it is not used.
The motivation of IPv6 flow labels is to allow differentiation of flows, even when the transport layer is not visible, for example due to fragmentation or encryption (more on these soon).
Some purported benefits of IPv6 flow labels are fixed field position making it efficient for hardware parsing and having a flow identifier that is independent from transport protocols.
On the face of it, IPv6 flow labels seem like an ideal solution to the problem of identifying packets to flows, however there are a few potential pitfalls to be aware of:
- Flow labels do not apply to IPv4 traffic (which is common in enterprise networks)
- Not all TCP/IP stacks use IPv6 flow labels. The requirement to set the flow label to a non-zero value is optional in the specification (RFC6437[2]). Indeed, the spec states that forwarding nodes must not rely on the flow label being present, or evenly distributed, so need to combine with the 5-tuple.
- Middleboxes (firewalls, load balancers etc.) may change the flow label. RFC6437 specifies that middleboxes must not change the label, except for “compelling operational security reasons“. This is a wide-open out for firewall vendors.
- Flow labels are not bidirectional. It is therefore necessary to identify both flow labels in a bidirectional flow in order to be able to comprehend metadata that relies on measuring parameters between packets in different directions. This then requires recourse back to comprehending the transport layer.
- There are proposals for reuse of the IPv6 flow label field for other purposes[3]
So, to sum up: Not all traffic is IPv6, not all IPv6 traffic implements the flow label and flow labels (where present) may not be reliable flow identifiers without combining with other flow keys, so IPv6 flow labels on their own are not a flow identification utopia.
IP Fragmentation
Another important flow-related consideration in the Internet layer is IP fragmentation. This can occur when it is necessary to break up an IP packet into smaller packets to allow transmission across a link where the maximum transmission unit (MTU) prevents the original packet from traversing it, as per example in Figure 4.
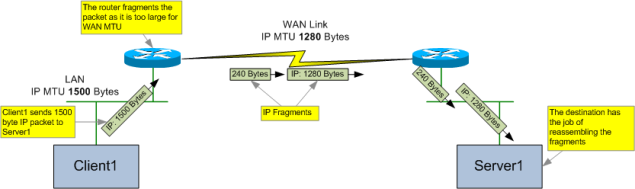
Figure 4 – Example IPv4 Fragmentation in a Network
When a router has an IPv4 packet with DF (Don’t Fragment) flag set, and the egress network has an MTU smaller than the packet, the router must drop the packet and send an ICMP “fragmentation needed and DF set” message to the source, advising them of the MTU that caused the drop. This is how Path MTU Discovery (PMTUD) works (see RFC1191), however there are times where this method of determining the path MTU may fail, causing fragmentation to occur instead.
If the packet is too large, but the DF is not set, then the router must fragment the packet into smaller packets that fit onto the egress network.
Fragmentation presents a new challenge for identifying packets to flows, as the transport header (TCP in the example diagram) is only present in the first fragment packet, as per Figure 5.
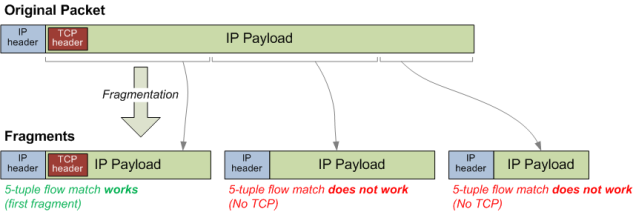
Figure 5 – Simplified Example of IP Fragmentation of Packets
The Internet layer has no knowledge of the structure of the transport layer (this is by design – layers are deliberately self-contained to enforce separation of concerns), so the Internet layer cannot copy transport headers to multiple fragments as it does not know its structure or boundary.
This leaves us with a problem when it comes to identifying packets to flows. If we don’t have a way of understanding fragments then the packets in Figure 4 will be seen as two separate flows, lowering the accuracy of our statistics. Furthermore, extra complication can be introduced if fragmentation happens multiple times across the connection, leading to multiple fragmentations[4].
The problem of fragmentation is reduced, however not eliminated, in IPv6. Intermediate devices such as routers cannot fragment IPv6 packets; however the source node can still fragment[5]. Indeed, fragmentation in IPv6 may be more of a problem than in IPv4 as it requires use of an IPv6 extension header[6].
If we reconsider the final flow definition from Part 1, we would need to add another section to deal with fragments, specifying logic that matches initial fragments based on Internet layer flags and fields, and then dynamically builds rules to match subsequent fragments into the correct flow records based on 3-tuple matches. This is a stateful operation that has some complexity; for example, at what point are these dynamic match rules cleaned up?
In the IPv4 header (see Figure 6), the MF (More Fragments) flag being set and/or the Fragment Offset being non-zero indicate that the packet is a fragment.

Figure 6 – IPv4 Packet Header showing Fragmentation Fields
For identification of IPv4 fragments to flows, the following logic is required:
| More Fragments (MF) Flag | Fragment Offset Field | Deduced Fragment Type |
| 0 | 0 | Not a fragment |
| 0 | non-zero | Last fragment |
| 1 | 0 | First fragment |
| 1 | non-zero | Intermediate fragment |
It is also necessary to use the Identification field to tie the fragments back together to the first fragment, so that the transport layer of the first fragment can be used to identify the packets to a flow. A question arises: should the flow count the number of reassembled packets or fragmented packets? The answer will depend on how you wish to use the flow data.
Fragmentation is not just an inconvenience for flow measurement; it should be avoided where possible because it reduces efficiency and can introduce security vulnerabilities[7].
Encryption / Tunnelling
Encryption can hide the transport layer flow keys necessary for identifying packets to flows. This is not the case when encryption occurs at the application layer (such as in HTTPS), but may be an issue in lower layer encryption protocols such as IPsec, and tunnelling protocols such as GRE. In these cases if the traffic is IPv6 then the flow label can used as an additional flow key to differentiate flows within the tunnels.
Non-IP Packets
What about non-IP packets? Are these not flows? We end this blog post by diving below the Internet layer into the link layer. There are a number of link layer protocols (examples: IPv4 ARP and DHCP) where it may be useful to have comprehension on over multiple packets. A security consideration is use of link layer connectivity as a method to carry out reconnaissance, attack or move laterally within a subnet. Failure to comprehend the flows of these non-IP packets might result in detection systems missing this activity.
Wrapping it all up
In this post we covered Internet layer considerations for defining flows, and found that IPv6 works with previous methods for flow identification, but it also brings to the table a possible benefit with IPv6 flow labels. However, these labels are not a complete solution for identifying packets to flows by themselves due to inconsistent use, so should instead be considered as an additional flow key to augment other keys. We also found that IP fragmentation is problematic for flow identification and that link layer (non-IP) flows could also be a consideration.
In the next post in this series, What is a Network Traffic Flow? (Part 3), we cover aspects of flow metadata, including how to transport it.
Further Reading
Paper (2018) that covers the topic well from an academic angle:
Footnotes
[1] See https://tools.ietf.org/html/rfc8200 for IPv6 specification.
[2] For IPv6 flow label specifics, see: https://tools.ietf.org/html/rfc6437
[3] For more on use and misuse of IPv6 flow labels, see: https://labs.ripe.net/Members/joel_jaeggli/ipv6-flow-label-misuse-in-hashing . Also see: https://tools.ietf.org/html/draft-fioccola-spring-flow-label-alt-mark-01 for example of a proposed reuse of the field.
[4] For an explanation see: https://www.quora.com/What-happens-to-the-More-Fragments-flag-when-a-packet-undergoes-multiple-fragmentation-in-TCP-IP
[5] Further reading on fragmentation in IPv6: https://asert.arbornetworks.com/ipv6-fragmentation/
[6] Fantastically good write-up from Geoff Huston about IPv6 fragmentation problems at https://www.potaroo.net/ispcol/2017-08/xtn-hdrs.html
[7] See: https://tools.ietf.org/id/draft-bonica-intarea-frag-fragile-01.html

2 thoughts on “What is a Network Traffic Flow? (Part 2)”